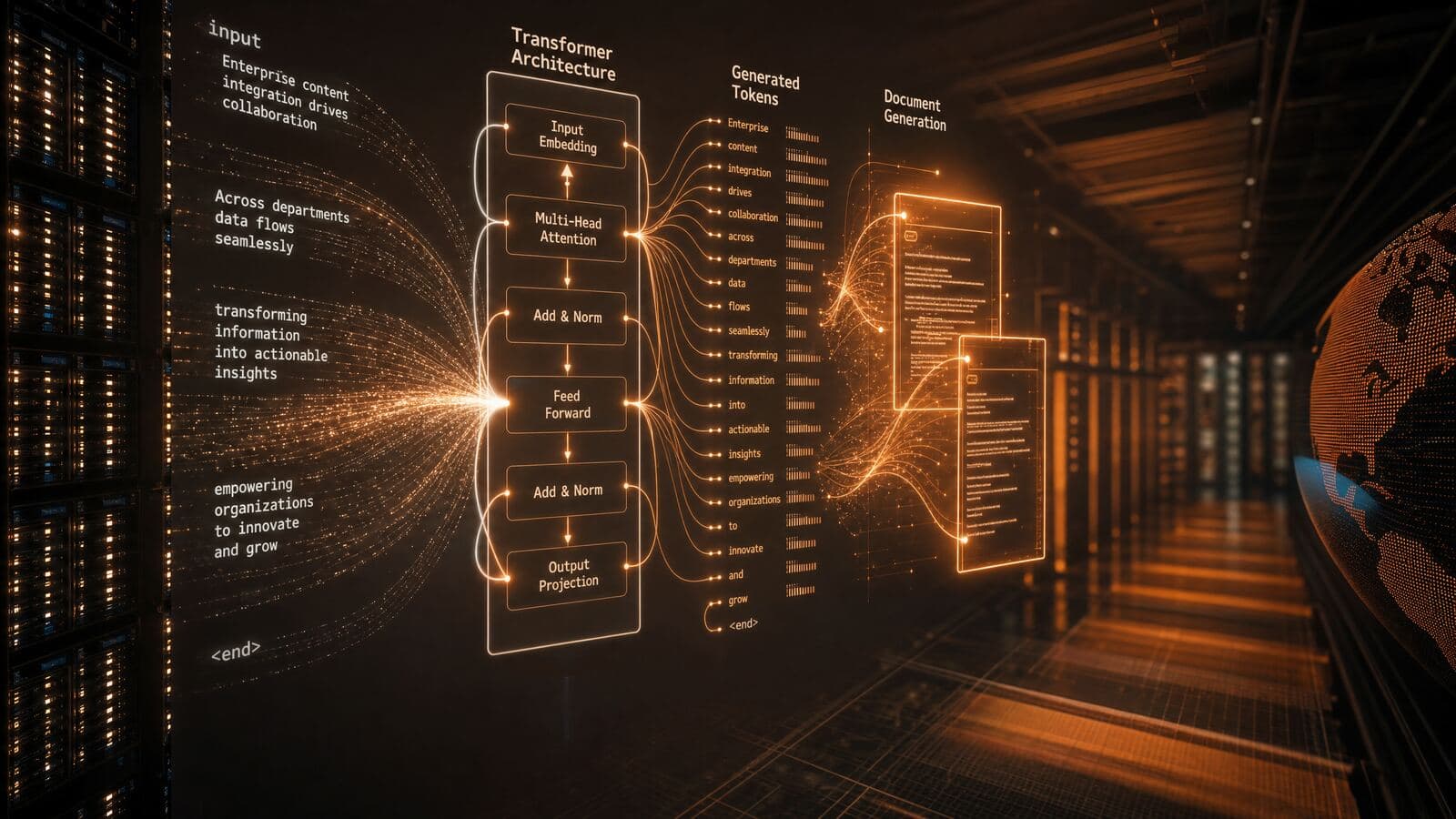
Generative AI & LLM Integration
Enterprise-Grade Language Model Solutions
Custom fine-tuning, prompt engineering, model serving, and evaluation pipelines - built for production reliability and cost efficiency.
Quick Answer
NeoBram delivers generative AI services that move beyond demos to production with LLM integration, evaluation pipelines, hallucination controls, governance, and ongoing optimization.
Why This Matters
LLMs Are Powerful. Making Them Production-Ready Is Hard.
Every enterprise wants to leverage large language models, but the gap between a ChatGPT demo and a production-grade LLM deployment is enormous. Fine-tuning, evaluation, serving, and cost management at scale require deep infrastructure expertise.
In 2026, the LLM landscape includes dozens of foundation models (GPT-4o, Claude 3.5, Gemini 2.0, Llama 3.1, Mistral), each with different strengths, pricing, and licensing models. Choosing the right model, fine-tuning it on your domain data, serving it efficiently, and ensuring output quality is a full-stack engineering challenge.
We've deployed LLM solutions for enterprises across industries - from custom fine-tuned models running on vLLM with PagedAttention for 10x throughput gains, to multi-model routing architectures that cut costs by 60% without sacrificing quality. Our evaluation pipelines catch regressions before they reach production.
Our Tech Stack
Production-Grade Tools We Deploy
Foundation Models
Fine-Tuning & Training
Prompt Engineering
Model Serving & Inference
Evaluation & Testing
Gateway & Routing
Cost Optimization
Guardrails & Safety
Architecture Deep-Dive
How We Build It
Custom LLM Fine-Tuning
LoRA/QLoRA fine-tuning on your enterprise data with Hugging Face PEFT. RLHF and DPO alignment for instruction-following quality. Evaluation-driven training loops with automated benchmarking.
- LoRA fine-tuning: train domain-specific adapters with <1% of parameters
- QLoRA: 4-bit quantized fine-tuning on a single A100 GPU
- RLHF and DPO alignment for enterprise-specific instruction following
- Unsloth for 2x faster training with 60% less GPU memory
- Automated benchmark evaluation after each training run
- Model merging (DARE, TIES) for combining multiple adapters
Enterprise Prompt Engineering
Systematic prompt design with LangChain, DSPy for automated prompt optimization, and structured output generation with Outlines. Beyond manual prompt writing - programmatic optimization.
- DSPy: compile prompts that optimize themselves on your eval data
- Outlines: guaranteed JSON output with schema validation
- Few-shot, chain-of-thought, and self-consistency prompting patterns
- Prompt versioning and regression testing with Promptfoo
- Context window management: summarization, compression, chunking
- Multi-turn conversation prompt design for enterprise workflows
Model Serving & Inference
High-throughput serving with vLLM (PagedAttention), continuous batching, and speculative decoding. Multi-model routing for cost optimization. A/B testing framework for model comparison.
- vLLM with PagedAttention: 10-24x throughput vs naive serving
- Continuous batching for maximum GPU utilization
- Speculative decoding: use small draft model to accelerate large model
- Multi-model routing: GPT-4o for complex tasks, Haiku for simple ones
- LiteLLM for unified API across 100+ providers with automatic fallbacks
- Self-hosted inference for data sovereignty with Llama 3.1 on vLLM
Evaluation & Quality Assurance
Automated evaluation pipelines with RAGAS, DeepEval, and LLM-as-Judge. Regression testing for prompt changes. Hallucination detection and factual grounding verification.
- RAGAS metrics: faithfulness, answer relevancy, context precision/recall
- DeepEval: 14+ metrics including hallucination and toxicity detection
- LLM-as-Judge: automated quality scoring using stronger models
- Regression testing: every prompt change tested against eval dataset
- A/B testing framework for comparing model versions in production
- Continuous monitoring with drift detection on output quality
Data Security, Governance & Safety
Enterprise AI demands enterprise-grade security. Every solution we deploy follows strict data sovereignty, safety, and compliance standards.
Data Sovereignty
- Your data stays in your infrastructure - always
- Deploy on your cloud (AWS, Azure, GCP) or on-premise
- No data leaves your environment
- Full compliance with regional data residency requirements
Model Safety & Guardrails
- NVIDIA NeMo Guardrails for content safety
- PII detection and redaction with Presidio
- Prompt injection defense and input sanitization
- Hallucination detection and factual grounding
Access Control & Audit
- Role-based access control for all AI systems
- Immutable audit logs for every interaction
- SOC 2 Type II, ISO 27001 compliance frameworks
- GDPR, HIPAA, and industry-specific regulations
Responsible AI
- Bias testing with Fairlearn and AI Fairness 360
- Model explainability via SHAP and LIME
- Transparency reports for stakeholders
- Continuous fairness monitoring in production
FAQ
Frequently Asked Questions
Start Your AI Transformation Today
Ready to unlock the full potential of AI for your enterprise? Let's build something extraordinary together.