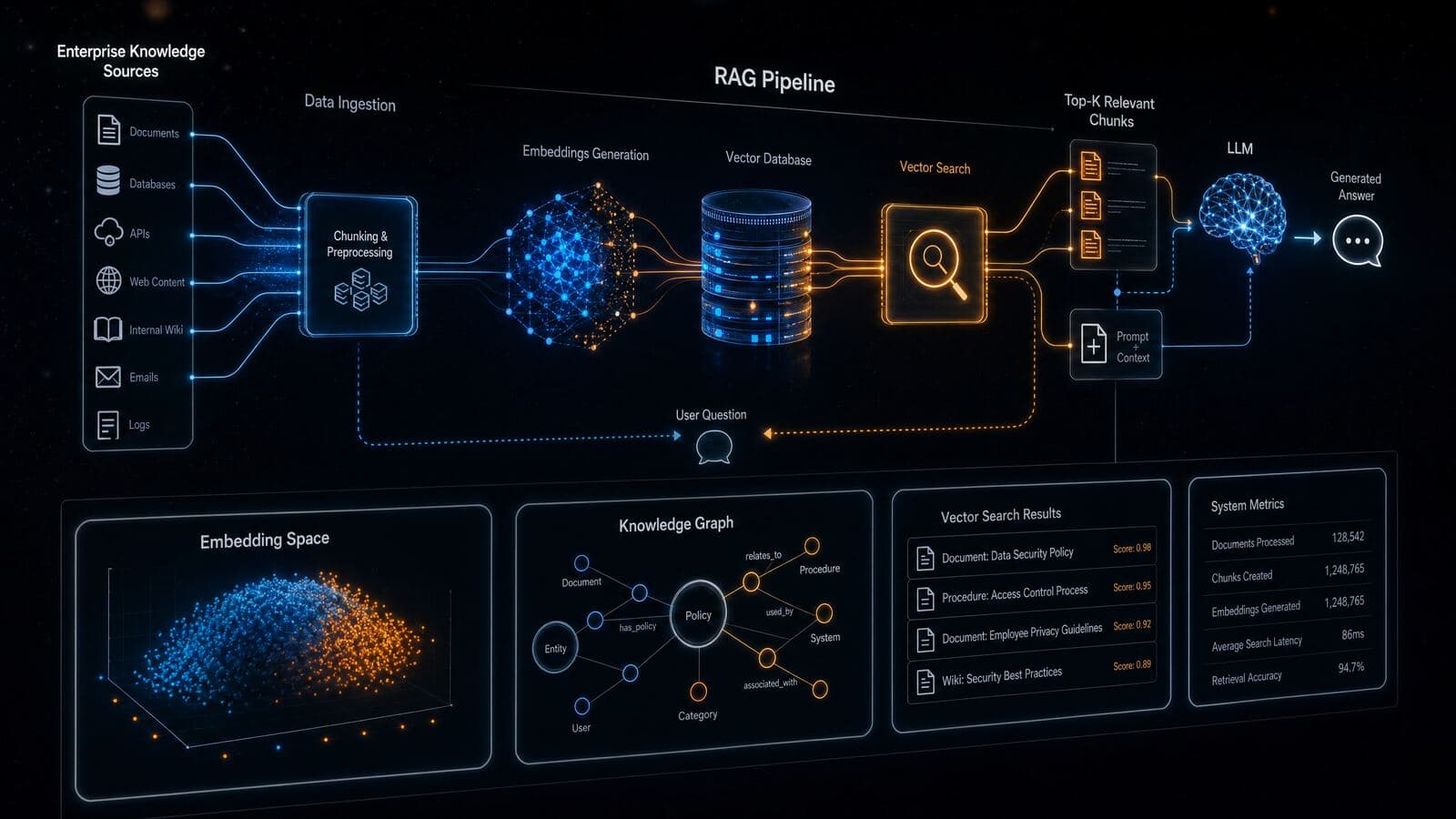
Factory-floor knowledge assistant
- Decision
- Which approved procedure or past event should a worker review for this situation?
- Minimum useful evidence
- Controlled SOPs, manuals, work instructions, issue history, revisions, owners and permissions.
- Acceptance
- Correct source retrieval, supported answer, visible citation, safe escalation and usable response time.
- Can fail when
- Documents conflict, obsolete records are returned, permissions leak or generated steps exceed the source.